

2025云服务器GPU技术全景与商业应用指南

随着AI大模型、元宇宙和科学计算的爆发式发展,2025年云服务器GPU技术迎来了革命性突破。本文将深度解析NVIDIA B100、AMD MI300X等新一代GPU架构,对比主流云服务商产品方案,并提供面向不同应用场景的选型指南。
2025年新一代GPU架构解析
NVIDIA B100 “Blackwell” 架构
2025年主流的NVIDIA B100 GPU基于新一代Blackwell架构,主要技术突破:
- 制程工艺: 台积电3nm工艺,晶体管数量达1400亿
- 计算性能: 2000 TFLOPS(FP16), 比A100提升5倍
- 显存配置: 144GB HBM3e,带宽达6TB/s
- 能效比: 性能功耗比提升40%,支持液冷方案
- 新特性: 第4代Tensor Core,支持FP8精度
AMD MI300X “CDNA 3” 架构
AMD 2025年旗舰计算GPU主要特点:
- 芯片设计: 3D Chiplet封装,CPU+GPU统一内存
- 计算性能: 1500 TFLOPS(FP16), 192个计算单元
- 显存容量: 192GB HBM3,带宽5.2TB/s
- 开放生态: 全面支持ROCm 6.0开源平台
阿里云EBMgn7i实例采用MI300X,在科学计算场景表现优异。
2025主流云计算GPU规格对比
| 型号 | 架构 | FP16算力 | 显存容量 | 显存带宽 | TDP | 主要云厂商 |
|---|---|---|---|---|---|---|
| NVIDIA B100 | Blackwell | 2000 TFLOPS | 144GB HBM3e | 6TB/s | 700W | 腾讯云、AWS、Google |
| AMD MI300X | CDNA 3 | 1500 TFLOPS | 192GB HBM3 | 5.2TB/s | 650W | 阿里云、华为云 |
| Intel Falcon Shores | XPU | 1200 TFLOPS | 128GB HBM3 | 4.8TB/s | 600W | Azure、Oracle |
| 华为Ascend 920 | 达芬奇 | 1800 TFLOPS | 96GB HBM2e | 4TB/s | 550W | 华为云 |
2025主流云服务商GPU实例对比
腾讯云GN10X实例
配置: 8×NVIDIA B100 + 96核CPU + 1TB内存
特点: 独家NVLink 5.0全互联(900GB/s带宽),支持万卡级弹性扩展
适用场景: 千亿参数大模型训练、实时渲染农场
价格: ¥89.5/小时 (按需)
查看详情阿里云EBMgn7i实例
配置: 8×AMD MI300X + 128核CPU + 1.5TB内存
特点: 统一内存架构,显存池化技术(1.5TB聚合显存)
适用场景: 科学计算、分子动力学模拟、气象预测
价格: ¥82.3/小时 (按需)
查看详情AWS P5实例
配置: 8×NVIDIA B100 + 96核CPU + 2TB内存
特点: 与SageMaker深度集成,全球15个区域部署
适用场景: 全球化AI服务、多区域协同训练
价格: $12.8/小时 (按需)
查看详情
应用场景与选型指南
1. 大语言模型训练
推荐配置: 8-64张NVIDIA B100,NVLink全互联
云服务商选择: 腾讯云的GN10X实例或AWS P5实例
优化建议: 使用FP8混合精度,梯度压缩技术可减少40%通信开销
3. 实时云游戏与元宇宙
推荐配置: NVIDIA B100或Intel Falcon Shores,支持光线追踪
云服务商选择: 腾讯云游戏解决方案或Azure PlayFab
优化建议: 使用AI超分辨率技术降低带宽消耗
2025云GPU技术趋势
- 3D堆叠GPU: 台积电SoIC技术实现计算单元垂直堆叠,性能密度提升3倍
- 光互连技术: 硅光模块替代传统铜互连,NVLink带宽突破1.6TB/s
- 存算一体: HBM内存集成计算单元,减少数据搬运能耗
- 量子-经典混合: GPU与量子计算单元协同工作,特定算法加速1000倍
- 绿色计算: 液冷+余热回收技术使PUE降至1.05以下
成本优化策略
- 弹性训练: 利用Spot实例进行容错训练,成本降低70%
- 模型压缩: 使用FP8/INT4量化技术,减少计算资源需求
- 梯度缓存: 减少GPU间通信频率,提升集群利用率
- 混合部署: 关键层使用B100,其他层使用MI300X降低成本
- 区域选择: 中西部数据中心价格比东部低30-40%
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END
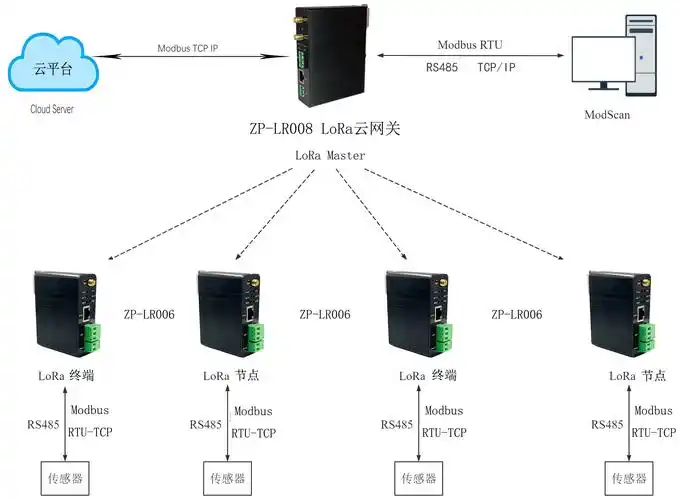
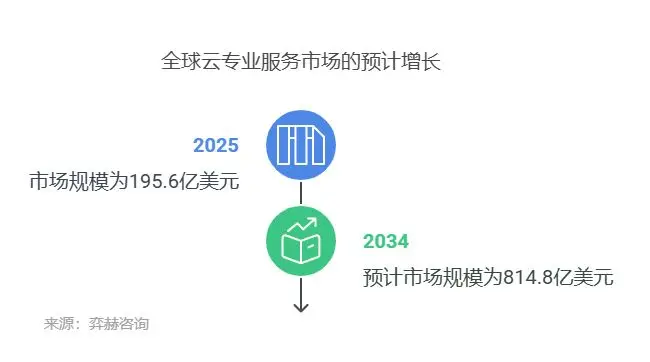
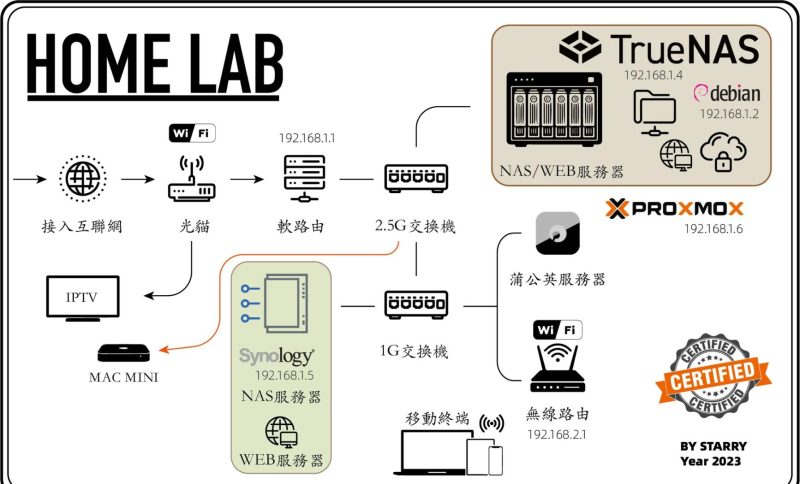
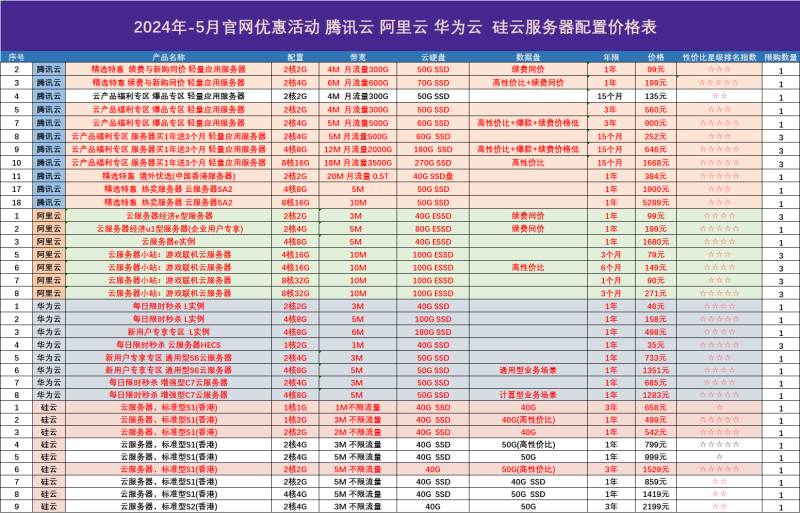
暂无评论内容