

GPU云主机全面解析:驱动AI与高性能计算的云端算力引擎
探索如何利用云端GPU算力加速人工智能、科学计算和图形渲染,无需巨额硬件投资
GPU云主机:重新定义计算能力的边界
GPU云主机是一种提供图形处理器(GPU)计算能力的云计算服务,专门设计用于处理大规模并行计算任务。与传统的CPU服务器相比,GPU拥有数千个计算核心,能够大幅加速计算密集型工作负载,成为人工智能、科学计算和图形处理领域的关键基础设施。
通过GPU云主机,企业和开发者能够按需访问顶级计算资源,无需承担购买和维护昂贵硬件的前期成本。这种模式特别适合需要间歇性高强度计算或快速扩展计算能力的应用场景。
GPU云主机的核心优势
卓越的计算性能
现代GPU云主机配备最新一代GPU(如NVIDIA H100、A100),提供高速显存配置(最高80GB HBM2e)、NVLink互联技术实现多卡协同计算,以及100Gbps+ InfiniBand网络架构,确保接近99.99%的运算稳定性保障。
弹性扩展与成本优化
相比自建GPU集群的巨额投入(单台DGX服务器成本超20万美元),云托管服务提供按需租用模式(小时计费灵活启停)、多层级配置(从单卡到多卡集群)以及跨可用区容灾能力,使整体计算成本降低40%-60%。
技术生态整合
主流GPU云服务提供商预装AI框架(如TensorFlow、PyTorch)、内置数据集,并提供简单直观的界面快速创建AI计算实例,大幅降低技术门槛和使用复杂度。
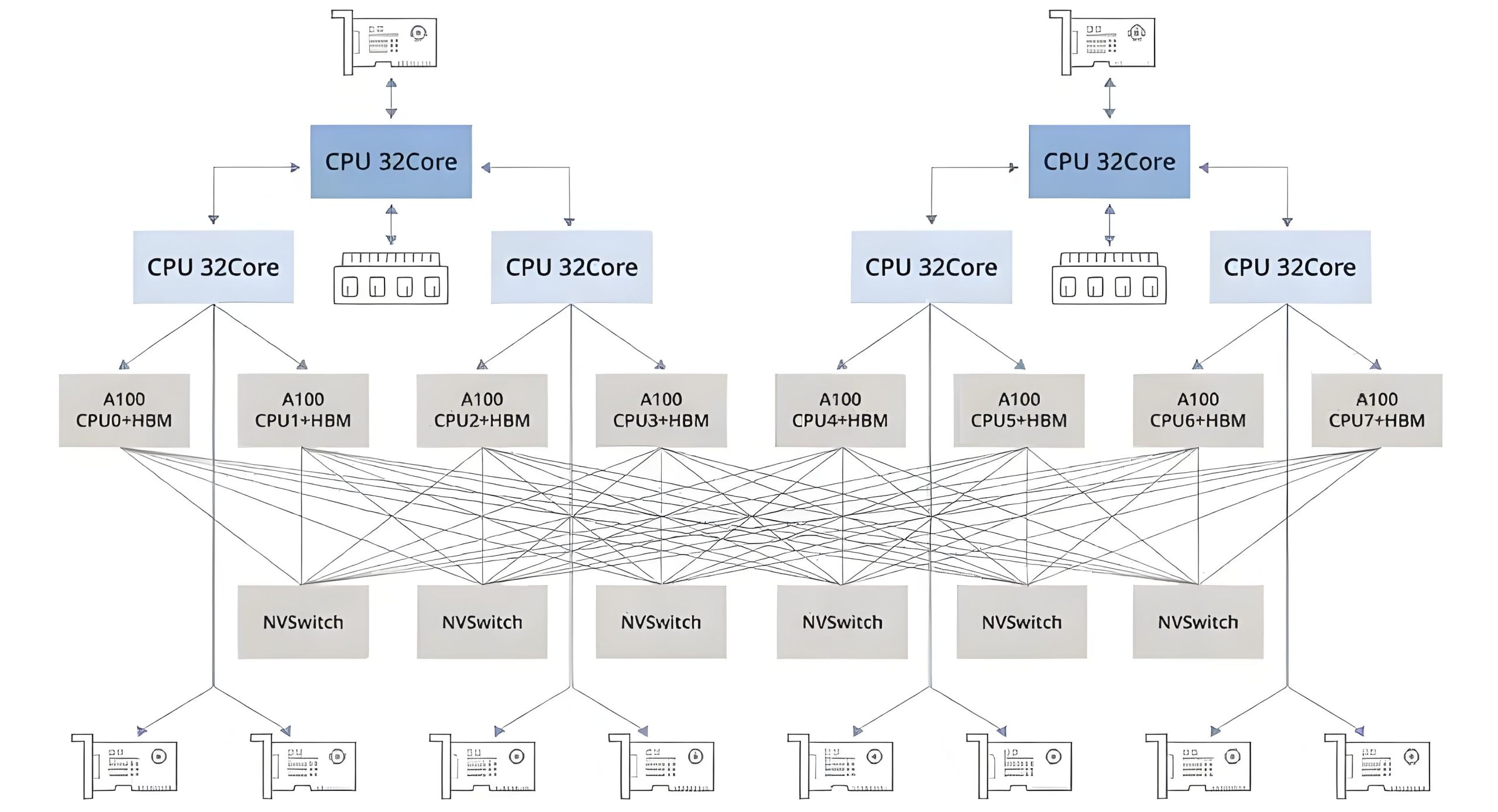
GPU云主机通过高速互联技术实现多节点协同计算
主流GPU云服务提供商对比
| 服务商 | GPU型号 | 核心优势 | 适用场景 |
|---|---|---|---|
| 阿里云 | NVIDIA V100 | 高达125TFlops深度学习性能,高可靠性 | 深度学习与AI训练 |
| 腾讯云 | NVIDIA A100/A30 | 弹性容器服务,高性能集群 | 科学计算、渲染 |
| 京东云 | Tesla A30/A10/P40/V100 | 多种配置选择,本地数据盘支持 | 机器学习、图形处理 |
| 北龙超云 | A800/A100/V100/3090 | 超算架构环境,IB高速互联 | 大规模预训练、科学计算 |
| Lambda | 最新NVIDIA架构 | 专注AI/ML基础设施,性价比高 | AI模型训练与推理 |
GPU云主机的应用场景
AI模型训练与推理
GPU云主机支持大语言模型(LLM)分布式训练、计算机视觉模型实时推理以及生成式AI应用(如Diffusion模型、GPT部署)。ResNet-50模型训练速度较CPU方案可提升17倍,大幅缩短迭代周期。
科学计算与仿真
适用于分子动力学模拟、气候预测建模、基因序列分析、计算金融学、计算流体动力学等多种科学计算场景,为研究人员提供高效计算能力,加速科学发现。
图形渲染与视觉处理
支持三维设计与渲染、影音动画制作、游戏开发、VR/AR内容生成和电影级CG制作。Blender Cycles渲染速度较CPU方案提升23倍,极大提高创作效率。
边缘计算与实时推理
基于全球边缘节点构成的算力网络,为高并发场景下的推理请求提供动态扩缩容能力,实现小于300ms的超低延时推理体验。
成本优化建议
对于长期项目,选择预留实例或包年包月方案可节省30%-50%成本。对于突发性计算需求,使用竞价实例可以大幅降低成本。建议根据工作负载特性混合使用不同计费模式,实现最优性价比。
如何选择GPU云主机服务
选择GPU云主机服务时需要考虑多个关键因素:
硬件配置
根据工作负载特性选择合适的GPU型号、显存容量和数量。新一代架构(如Hopper/Ada Lovelace)提供更高计算效率和能效比。同时需要匹配足够的CPU核心、内存和存储资源。
网络性能
检查跨地域传输速率与延迟指标,特别是RDMA网络支持(如25Gbps以上),对于多节点训练任务至关重要。高速互联技术(如NVLink、InfiniBand)可大幅提升多卡协同效率。
软件生态
评估预装软件栈(如CUDA、cuDNN、框架支持)和工具链完整性。一站式平台(如Lambda Stack)集成PyTorch、TensorFlow、CUDA等工具,便于快速部署和开发。
安全与合规
确保服务商通过SOC2/ISO27001等安全认证,提供数据加密方案和私有网络隔离机制。金融级客户可选择配备SGX可信执行环境的服务方案。
注意事项
使用GPU云主机时需要注意隐藏费用(如出口带宽费用)、数据安全机制(加密和备份策略)以及资源可用性(特别是最新一代GPU)。建议通过概念验证测试验证性能是否符合预期,并仔细阅读服务等级协议(SLA)。
GPU云主机部署最佳实践
性能优化策略
启用Tensor Core和混合精度训练可以大幅提升计算性能并减少显存使用。使用梯度累积和模型并行技术可以解决显存限制问题。配置适当的批处理大小和学习率调度器可以优化训练稳定性和收敛速度。
数据管道优化
使用TFRecords或WebDataset格式存储训练数据,减少I/O瓶颈。配置多进程数据加载和预处理,确保GPU计算单元持续得到数据供应。利用内存映射文件或高速缓存加速数据访问。
监控与调试
实施全面的性能监控(包括GPU利用率、显存使用、温度指标),设置自动化警报。使用Nsys、DLProf等性能分析工具识别计算瓶颈,优化模型架构和训练流程。
未来发展趋势
GPU云主机市场正经历快速演进,主要趋势包括:
绿色计算
液冷技术普及使PUE(电源使用效率)降至1.1以下,大幅降低计算碳足迹。可再生能源供电和碳抵消计划成为服务商差异化竞争因素。
混合架构
CPU+GPU+量子计算混合调度架构兴起,根据不同计算任务特性动态分配最优计算资源。专用处理单元(如DPU、IPU)进一步优化数据流和处理效率。
边缘协同
中心云与边缘GPU节点的协同推理成为标准架构,实现低延迟响应和数据隐私保护的平衡。5G和边缘计算技术发展推动分布式GPU计算范式普及。
常见问题解答
GPU云主机适合哪些业务场景?
适用于需要并行计算的场景,包括但不限于:大规模神经网络训练、3D影视渲染、流体力学仿真、密码破解等需要大量矩阵运算的工作负载。
如何选择显卡型号?
Tesla系列适合双精度计算,RTX系列侧重图形处理,A100适配Transformer等大模型。具体需根据框架的CUDA核心利用率进行测试验证。
数据安全如何保障?
主流供应商提供存储加密、私有网络隔离、GPU资源独占分配等安全机制。敏感数据可考虑使用本地化部署或混合云方案。
自建集群与GPU云主机的成本差异?
对于间歇性计算需求,GPU云主机可节省60%以上总拥有成本(TCO)。但对于持续满载工作负载,自建集群可能在2-3年内更具经济性。
如何优化GPU云主机的使用成本?
采用自动扩缩容策略,根据负载动态调整资源;使用竞价实例处理容错性强的任务;优化算法减少不必要的计算;选择适合而非最高的配置规格。
结语
GPU云主机已成为人工智能和高性能计算领域的关键基础设施,通过提供弹性、可扩展的顶级计算资源,降低了先进计算技术的门槛。随着绿色计算、混合架构和边缘协同等技术的发展,GPU云主机将继续推动各行业的数字化转型和创新突破。
选择适合的GPU云主机服务需要综合考虑计算需求、成本约束和技术要求。通过合理规划和优化,企业和研究机构可以充分利用这一强大工具,加速创新进程,在竞争激烈的技术环境中保持领先地位。
暂无评论内容