

OpenClaw部署实战全解:从单机到云端的一站式指南
无论是树莓派上的轻量实验,还是云服务器上的生产级集群,OpenClaw的部署路径比想象中更宽广。这份指南将拆解每一种可能,帮你找到最适合自己的那一条。
部署,是所有软件从代码变成生产力的最后一公里。对于OpenClaw这样一个兼具对话与执行能力的AI代理来说,部署方案的选择直接决定了它能发挥多大的价值。把它装在一台永不关机的云服务器上,它就是一个全天候的数字员工;把它塞进树莓派,再配上本地大模型,它就是完全离线的家庭智能枢纽。不同的硬件、不同的网络环境、不同的隐私要求,会指向截然不同的部署策略。
市面上关于OpenClaw的安装教程已经不少,但大多聚焦于“如何把服务跑起来”这个单一目标。这篇内容想做得更深入一些——它不仅会覆盖脚本、Docker、源码三种安装路径,还会花大量篇幅去探讨部署之后的那些事情:如何加固安全、如何规划目录结构让后期维护不头疼、如何设计一套可持续的备份与监控方案。对于已经跑通基础安装的人,这些内容或许比初始安装更有参考价值。
部署之前的决策:选好你的“房子”
OpenClaw对硬件的要求并不高,一台2核CPU、2GB内存的设备就能让它稳定运行。但“能跑”和“跑得好”之间,仍然有一系列变量需要权衡。
本地部署:数据主权放在第一位
如果你处理的数据比较敏感,或者单纯不喜欢把文件交给云端处理,本地部署是首选。它可以是你的主力工作电脑、一台闲置的迷你主机,甚至是一块树莓派。本地部署的好处很实在:数据完全不离开物理设备,响应延迟极低,而且不需要为云资源付费。缺点也很明显——你的设备必须持续开机,否则代理就跟着休眠了。对于偶尔使用的场景,这不算什么;但如果希望OpenClaw在深夜自动抓取数据、在清晨生成日报,就需要专门的硬件来承担“永不离线”的角色。
云服务器部署:全天候在线的保障
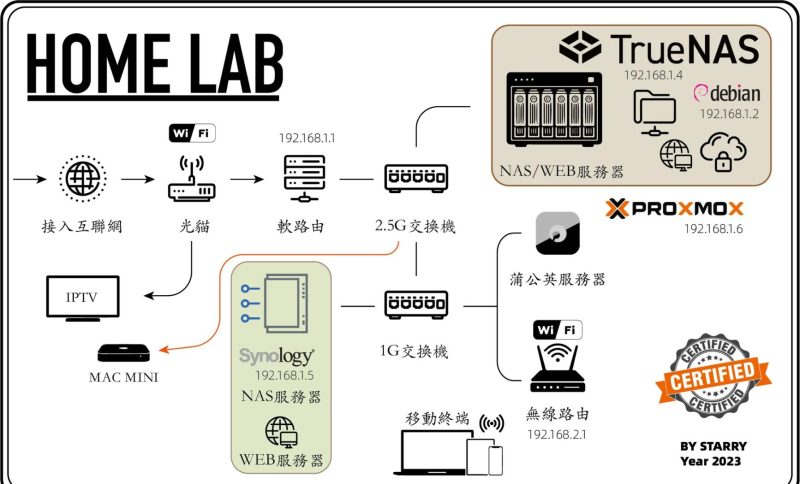
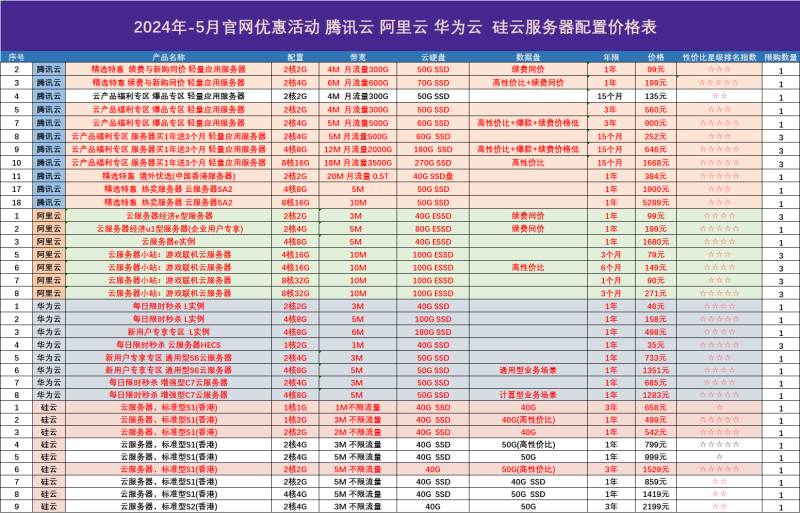
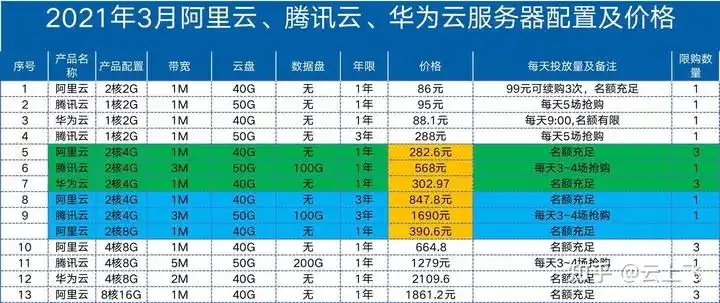
把OpenClaw放到云上,是大多数严肃用户的最终选择。一台基础配置的轻量应用服务器,月费不过几十元,却能换来24小时不间断的服务和固定的公网IP。国内主流的云服务商都提供了非常适合的选项:腾讯云的轻量应用服务器内置了Docker镜像,可以无缝对接微信通道;阿里云的ECS和函数计算都推出了OpenClaw的快速部署模板;华为云则为鲲鹏和昇腾做了专门的容器优化;UCloud的轻量主机性价比在个人开发者圈子里一直有良好口碑。
选择云服务器时,地域是个需要留意的因素。如果你主要通过微信与OpenClaw交互,服务器放在中国大陆机房延迟最低,但微信公众平台的对接需要ICP备案的域名。如果暂时不想处理备案,可以选中国香港节点,延迟同样可控,且免备案。另外,云服务器的安全组一定要在部署前就配置好,只开放必要的端口,避免因为疏忽导致代理被恶意操控。
混合模式:鱼与熊掌可以兼得
还有一种更灵活的用法:敏感任务交给本地实例处理,需要公网访问或高强度算力的任务则由云端实例承担。两个实例之间可以通过共享的技能和记忆目录进行同步。这种混合模式兼顾了数据隐私和服务可用性,适合对两者都有较高要求的用户。部署时只需要注意两个实例的配置版本保持同步,以及网络连通性足够稳定。
核心组件的部署路径详解
OpenClaw的核心架构可以简单概括为“网关+智能体”两层结构。网关负责接收消息、处理认证、分发任务;智能体则承担理解意图、规划执行、调用技能的职责。在实际部署中,这两层通常被打包成两个独立的容器,通过Docker Compose统一管理。下面逐一拆解每种安装方式的具体步骤和适用场景。
方式一:官方脚本,即开即用
这是最快捷的入门路径。只需在终端执行一行命令:
curl -fsSL https://openclaw.ai/install.sh | bash
脚本会自动检测操作系统和Node版本,完成依赖安装和路径配置。安装成功后,运行openclaw指令即可进入交互式配置向导,引导你完成模型API密钥、消息通道等核心设置。脚本安装的优势是速度,适合初次接触、想立刻体验的用户。但它直接将程序写入系统环境,卸载和升级相对麻烦,不建议用于生产级部署。
方式二:Docker Compose,生产级标准
Docker部署提供了最干净的隔离和最简单的回滚能力。以下是一个生产环境可用的Compose模板,与基础版相比增加了资源限制、日志轮转和健康检查:
version: '3.8'
services:
gateway:
image: openclaw/gateway:stable
container_name: openclaw-gateway
ports:
- "127.0.0.1:8080:8080"
volumes:
- ./config:/app/config:ro
- ./logs/gateway:/app/logs
environment:
- API_KEY=你设定的安全密钥
- MODEL_PROVIDER=openai
- MODEL_API_KEY=你的模型密钥
restart: unless-stopped
logging:
driver: "json-file"
options:
max-size: "15m"
max-file: "5"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 3
agent:
image: openclaw/agent:stable
container_name: openclaw-agent
depends_on:
gateway:
condition: service_healthy
volumes:
- ./skills:/app/skills
- ./memory:/app/memory
- ./logs/agent:/app/logs
environment:
- GATEWAY_URL=http://gateway:8080
- MEMORY_PATH=/app/memory
restart: unless-stopped
logging:
driver: "json-file"
options:
max-size: "15m"
max-file: "5"
有几个细节值得注意。第一,网关端口映射到了127.0.0.1而非0.0.0.0,这意味着它只监听本机,外部必须通过Nginx等反向代理才能访问,安全系数更高。第二,配置文件挂载使用了只读模式(:ro),防止容器内部进程意外修改配置。第三,健康检查确保智能体在网关就绪后才启动,避免启动顺序引发的异常。如果你在腾讯云或阿里云购买的轻量服务器上部署,这个模板可以直接上传使用。
方式三:源码构建,深度定制
对于需要修改框架源码的高级用户,从GitHub克隆仓库并本地构建是唯一的选择。步骤包括克隆仓库、安装依赖、执行构建,最终生成可执行文件。这条路提供了最大的自由度,但也要求后续手动跟进官方更新。通常在两种场景下推荐源码部署:一是你需要修改核心逻辑,比如增加自定义的认证插件;二是你希望在完全离线的环境中运行,需要从源码级剔除所有网络请求。
消息通道:让代理“听见”你
OpenClaw本身没有图形界面,它依赖消息通道来接收和回复信息。最常用的通道是Telegram和微信。Telegram的配置极其简单,找BotFather创建一个机器人,拿到Token填入配置文件即可,对新手友好。微信通道则需要微信公众平台的AppID和AppSecret,还需要一个公网可访问的域名作为回调地址,流程稍长但更贴近国内用户的日常习惯。
配置微信通道时,最容易卡住的环节是回调验证。微信服务器会发送一个GET请求到你的回调地址,要求你在极短时间内返回正确的签名。如果Token、EncodingAESKey或URL路径有任何一个配置错误,验证就会反复失败。建议在配置微信之前,先用Telegram验证整套系统的功能是否正常,排除掉代码层面的问题后再集中精力解决微信回调。此外,微信通道要求服务器必须在中国大陆且域名已完成ICP备案,中国香港或海外的云服务器无法通过验证,这一点在选择云服务器地域时就要考虑进去。
模型后端:给代理一颗合适的大脑
模型是OpenClaw的决策中枢,它的选择直接影响代理的智能水平、响应速度和运行成本。配置文件中的MODEL_PROVIDER字段控制着模型来源。使用云端API(如OpenAI、阿里云百炼、百度智能云文心)可以获得最快的推理速度和最低的维护成本,适合大多数场景。如果对数据隐私有极高要求,可以用Ollama在本地部署一个开源模型,将MODEL_PROVIDER设为ollama。本地模型的推理速度取决于硬件,内存建议至少8GB,参数规模以7B到13B为宜。云端和本地模型可以同时配置,按任务类型灵活切换,比如敏感数据用本地模型处理,一般任务交给云端加速。
目录结构与持久化规划
部署初期如果不设计好目录结构,后期迁移和备份会非常痛苦。建议采用以下目录布局:
/openclaw
├── config/ # 网关与通道配置
├── skills/ # 自定义技能脚本
├── memory/ # 长期记忆数据
├── logs/
│ ├── gateway/ # 网关日志
│ └── agent/ # 智能体日志
└── backups/ # 定期备份存放点
这套结构清晰地把数据与程序分离。当需要迁移服务器时,只需打包整个/openclaw目录,在新服务器上拉起Docker Compose并挂载对应的卷即可恢复全部状态。memory目录尤其重要,它存储着代理学到的用户偏好和长期记忆,丢失后需要相当长的时间才能重新积累。建议用crontab定时任务配合rsync,将memory和skills目录同步到另一台设备或云对象存储(如腾讯云COS或阿里云OSS)。
安全加固:给数字助理穿上铠甲
由于OpenClaw具备操作系统级的执行能力,安全配置绝不能马虎。以下措施建议在部署完成后逐一落实:
- 最小权限原则:在配置文件中设置
ALLOWED_PATHS,限制代理只能访问几个必要的目录,避免误操作或恶意指令波及重要系统文件。 - 操作确认机制:开启
require_confirmation选项,涉及文件删除、对外网络请求等高风险操作时,代理必须先向你发送确认请求,获得批准后才执行。 - 网络隔离:如果不需要代理访问互联网,可以在Docker Compose中为容器设置内部网络,完全断开其出站连接。大多数自动化任务其实并不需要公网访问。
- 日志审计:保留完整的执行日志,并定期审查。日志中记录了代理的每一步操作,是发现异常行为的第一手资料。
- 定期更新:无论是Docker镜像还是技能包,都应保持更新,及时修复已知漏洞。
技能生态:从“可用”到“好用”的跃升
刚部署好的OpenClaw只能完成最基本的对话与文件操作,真正的生产力飞跃来自技能扩展。社区技能仓库(ClawHub)已累积了覆盖数十个领域的数万个技能包。通过聊天指令/install即可添加,也可以直接克隆Git仓库到skills目录。常见的自动化需求几乎都有现成方案:文件自动归类、RSS监控与摘要、股价异动提醒、定时备份、邮件批量处理等。
对于有编程基础的用户,编写自己的技能是让OpenClaw变得独一无二的关键。一个技能就是一个独立的脚本文件,写好描述信息后放入skills目录,代理会在下一次任务规划时自动发现并加载。建议从简单脚本开始,比如每天固定时间抓取特定网页并生成摘要,逐步扩展到更复杂的多步骤流程。技能开发时注意遵守目录规范,做好错误处理和日志输出,这样调试和共享都会方便许多。
运维监控:让代理自己盯住自己
部署上线后的OpenClaw需要持续的运维关注,但运维本身也可以部分交给OpenClaw来完成。可以编写一个“自检技能”,定时检查容器状态、磁盘使用率、CPU负载等关键指标,一旦超出阈值就通过消息通道发送告警。同时,利用日志轮转策略避免磁盘被日志撑满——Docker的logging配置可以设置单个日志文件的最大体积和保留数量。
对于运行在云服务器上的实例,还可以结合云厂商的监控服务。例如腾讯云监控和阿里云云监控都支持自定义告警规则,当CPU持续高位或网络流量异常时可以自动通知。这些现成的云服务与OpenClaw的自检脚本形成双层防护,即使代理自身出现问题,外部监控也能及时捕获。
进阶:从单实例到轻量集群
当单个OpenClaw实例需要同时服务多个用户或承担多种类型的任务时,可以考虑“一网关多智能体”的集群架构。网关作为统一入口负责消息分发,多个智能体容器分别挂载不同的技能和记忆,处理不同领域的任务。这种架构在同一台服务器上即可实现,只需用不同的Compose项目名启动多组容器,并为每个智能体分配不同的技能目录。
如果任务量继续增长,可以引入消息队列(如Redis或RabbitMQ)来解耦网关和智能体,实现异步处理与弹性伸缩。此时网关将任务推入队列,多个智能体实例竞争消费,处理完成后将结果推回网关。这种架构对开发者有一定技术要求,但它展示了OpenClaw作为基础设施的扩展潜力——它不是一成不变的玩具,而是可以随着需求生长为真正的自动化中枢。
写在部署完成之后
当你把OpenClaw稳稳地部署好,发出第一条消息并收到回应,或许会感到一种熟悉的成就感——就像组装完一台电脑,按下开机键,屏幕亮起的瞬间。但这种感觉还只是一个开始。真正的乐趣在于后续的调教与磨合:你为它编写一个专属技能,它帮你省下每周数小时重复劳动;你加固了一层安全策略,它在一次意外的恶意请求前稳住了阵脚;你设计了一套备份方案,它在一次磁盘故障后毫发无损地恢复了全部记忆。
部署不是终点,而是人与机器协同进化的起点。OpenClaw的价值会在日复一日的使用中逐渐显现——它记住你的习惯,适应你的节奏,成为数字生活中那个最沉默也最可靠的存在。这个过程,或许就是技术赋予我们最踏实的一种自由。
本文部署建议基于开源社区公开文档及大量实践经验汇总,文中提及的云服务商链接均为外部参考,无商业推荐意图。
暂无评论内容